Curation module
Note
As of July 2024, this module is still under construction and quite experimental. The API of some of the functions could be changed/improved from time to time.
Curation with the SortingAnalyzer
The SortingAnalyzer, as seen in previous modules,
is a powerful tool to postprocess the spike sorting output, as it can compute many
extensions and metrics to further characterize the spike sorting results.
To facilitate the spike sorting workflow, the SortingAnalyzer
can also be used to perform curation tasks, such as removing bad units or merging similar units.
Here’s an example of how to use the SortingAnalyzer to remove
a subset of units from a spike sorting output and to perform some merges:
from spikeinterface import create_sorting_analyzer
sorting_analyzer = create_sorting_analyzer(sorting=sorting, recording=recording)
# compute some extensions
sorting_analyzer.compute(["random_spikes", "templates", "template_similarity", "correlograms"])
# remove some units
remove_unit_ids = [1, 2]
sorting_analyzer2 = sorting_analyzer.remove_units(remove_unit_ids=remove_unit_ids)
# merge units 4 and 5, and separately merge units 7, 8 and 12
merge_unit_groups = [[4, 5], [7, 8, 12]]
sorting_analyzer3 = sorting_analyzer2.merge_units(
merge_unit_groups=merge_unit_groups,
censored_period_ms=0.5,
merging_mode="soft"
)
Importantly, all the extensions that were computed on the original SortingAnalyzer
(sorting_analyzer) are automatically propagated to the returned new
SortingAnalyzer objects (sorting_analyzer2, sorting_analyzer3).
In particular, the merging steps supports a few interesting and useful functions.
If censored_period_ms is set, the function will remove spikes that are too close in time after the merge
(in the case above, closer than 0.5 ms).
The merging_mode parameter can be set to "soft" (default) or "hard". The "soft" mode will
try to smartly combine the existing extension data (e.g. templates, template similarity, etc.)
to estimate the merged units’ data, when possible. This is the fastest mode, but it can be less accurate.
The "hard" mode will simply merge the spike trains of the units and recompute the extensions on the
merged spike train. This is more accurate but slower, especially for the extensions that need to traverse the
raw data (e.g., spike amplitudes, spike locations, amplitude scalings, etc.).
Automatic curation tools
The spikeinterface.curation module provides several automatic curation tools to clean spike sorting outputs.
Many of them are ported, adapted, or inspired by Lussac
([Llobet]).
Remove duplicated spikes and redundant units
There are some convenient functions of the curation module allows you to remove redundant units and duplicated spikes from the sorting output.
The remove_duplicated_spikes() function removes
duplicated spikes from the sorting output. Duplicated spikes are spikes that are
occur within a certain time window for the same unit.
from spikeinterface.curation import remove_duplicated_spikes
# remove duplicated spikes from BaseSorting object
clean_sorting = remove_duplicated_spikes(sorting, censored_period_ms=0.1)
The censored_period_ms parameter is the time window in milliseconds to consider two spikes as duplicated.
The remove_redundand_units() function removes
redundant units from the sorting output. Redundant units are units that share over
a certain percentage of spikes, by default 80%.
The function can act both on a BaseSorting or a SortingAnalyzer object.
from spikeinterface.curation import remove_redundant_units
# remove redundant units from BaseSorting object
clean_sorting = remove_redundant_units(
sorting,
duplicate_threshold=0.9,
remove_strategy="max_spikes",
align=False,
)
# remove redundant units from SortingAnalyzer object
# note this returns a cleaned sorting
clean_sorting = remove_redundant_units(
sorting_analyzer,
duplicate_threshold=0.9,
remove_strategy="minimum_shift",
)
# in order to have a SortingAnalyer with only the non-redundant units one must
# select the designed units remembering to give format and folder if one wants
# a persistent SortingAnalyzer.
clean_sorting_analyzer = sorting_analyzer.select_units(clean_sorting.unit_ids)
We recommend using the SortingAnalyzer approach, since the minimum_shift strategy keeps
the unit (among the redundant ones), with a better template alignment.
Auto-labeling units
The curation function allows you to automatically label units based on a set of rules.
The simplest way to do so is to use the threshold_metrics_label_units() function,
which applies a set of thresholds based on the available metrics (template/quality metrics, etc.):
from spikeinterface.curation import threshold_metrics_label_units
# auto-label units based on some thresholds
labels = threshold_metrics_label_units(
sorting_analyzer=sorting_analyzer,
thresholds={
"snr": {"greater": 5},
"rp_contamination": {"less": 0.2},
},
pass_label="good",
fail_label="bad",
column_name="simple_threshold"
)
The returned labels is a pandas.DataFrame with the unit_ids as index and the assigned labels in the simple_threshold column.
A second and much more powerful way to auto-label units is to run Bombcell [Fabre], a tool that uses a large set of
metrics and heuristic rules based on metrics to classify units as noise, mua or good (and even non-soma).
To run Bombcell, you can use the bombcell_label_units():
from spikeinterface.curation import bombcell_label_units, bombcell_get_default_thresholds
# auto-label units with Bombcell
labels = bombcell_label_units(
sorting_analyzer=sorting_analyzer,
thresholds=bombcell_get_default_thresholds()
)
The labels are returned in a pandas.DataFrame with the unit_ids as index and the assigned labels in the
bombcell_label column.
You can also provide your own set of thresholds to the bombcell_label_units function.
Finally, a third way to auto-label units is to train machine learning models based on the available metrics and use the
trained model to predict labels for the units. This is done by the UnitRefine [Jain] tool, which is based on a
random forest classifier trained on a large dataset of manually curated units.
Classification is done in two steps: first, the model predicts whether a unit is noise or neural; then,
for the non-noise units, the model predicts whether they are sua (aka good) or mua.
We provide pre-built models on HuggingFace,
and you can use the unitrefine_label_units() function to apply the model to your data:
from spikeinterface.curation import unitrefine_label_units
# auto-label units with UnitRefine
labels = unitrefine_label_units(
sorting_analyzer=sorting_analyzer,
noise_neural_model="SpikeInterface/UnitRefine_noise_neural_classifier",
sua_mua_model="SpikeInterface/UnitRefine_sua_mua_classifier"
)
The labels are returned in a pandas.DataFrame with the unit_ids as index and the assigned labels in the
unitrefine_label column.
Auto-merging units
The compute_merge_unit_groups() function returns a list of potential merges.
The list of potential merges can be then applied to the sorting output.
compute_merge_unit_groups() has many internal tricks and steps to identify potential
merges. It offers multiple “presets” and the flexibility to apply individual steps, with different parameters.
Read the function documentation carefully and do not apply it blindly!
from spikeinterface import create_sorting_analyzer
from spikeinterface.curation import compute_merge_unit_groups
analyzer = create_sorting_analyzer(sorting=sorting, recording=recording)
# some extensions are required
analyzer.compute(["random_spikes", "templates", "template_similarity", "correlograms"])
# merges is a list of unit pairs, with unit_ids to be merged.
merge_unit_pairs = compute_merge_unit_groups(
sorting_analyzer=analyzer,
preset="similarity_correlograms",
)
# with resolve_graph=True, merges_resolved is a list of merge groups,
# which can contain more than two units
merge_unit_groups = compute_merge_unit_groups(
sorting_analyzer=analyzer,
preset="similarity_correlograms",
resolve_graph=True
)
# here we apply the merges
analyzer_merged = analyzer.merge_units(merge_unit_groups=merge_unit_groups)
Currently, we support the following presets: ‘similarity_correlograms’, ‘temporal_splits’, ‘x_contaminations’, ‘feature_neighbors’ and ‘slay’. Find out more about SLAy in their preprint: [Koukuntla].
There is also the convenient auto_merge_units() function that combines the
compute_merge_unit_groups() and merge_units() functions.
This is a high level function that allows you to apply either one or several presets/lists of steps in one go. For example, let’s
assume you want to apply the “x_contamination” preset, but iteratively and with slightly different parameters: first,
you want to focus on the templates that are very similar, according to their template similarities, before
considering those that might be more distant. Such a greedy and iterative scheme has been proved to be less
prone to wrong merges. To do so, you’ll need to do the following:
from spikeinterface import create_sorting_analyzer
from spikeinterface.curation import auto_merge_units
analyzer = create_sorting_analyzer(sorting=sorting, recording=recording)
# some extensions are required
analyzer.compute(["random_spikes", "templates", "template_similarity", "correlograms"])
analyzer.compute("unit_locations", method="monopolar_triangulation")
template_diff_thresh = [0.05, 0.15, 0.25]
presets = ["x_contaminations"] * len(template_diff_thresh)
steps_params = [
{"template_similarity": {"template_diff_thresh": i}}
for i in template_diff_thresh
]
analyzer_merged = auto_merge_units(
analyzer,
presets=presets,
steps_params=steps_params,
recursive=True,
**job_kwargs,
)
The extra keyword recursive specifies that for each presets/sequences of steps, merges are performed
until no further merges are possible. The job_kwargs are the parameters for the parallelization.
Be careful: the merges can not be reverted, so be sure to not erase your analyzer and instead create a new one
Manual curation
While automatic curation tools can be very useful, manual curation is still widely used to clean spike sorting outputs and it is sometimes necessary to have a human in the loop.
Curation format
SpikeInterface internally supports a JSON-based manual curation format. When manual curation is necessary, modifying a dataset in place is a bad practice. Instead, to ensure the reproducibility of the spike sorting pipelines, we have introduced a simple and JSON-based manual curation format. This format defines at the moment : merges + deletions + manual tags. The simple file can be kept along side the output of a sorter and applied on the result to have a “clean” result.
This format has two part:
definition with the folowing keys:
“format_version” : format specification
“unit_ids” : the list of unit_ds
- “label_definitions”list of label categories and possible labels per category.
Every category can be exclusive=True (only one label) or exclusive=False (several labels possible).
manual output curation with the folowing keys:
“manual_labels”
“merge_unit_groups”
“removed_units”
Here is the description of the format with a simple example (the first part of the format is the definition; the second part of the format is manual action):
{
"format_version": "1",
"unit_ids": [
"u1",
"u2",
"u3",
"u6",
"u10",
"u14",
"u20",
"u31",
"u42"
],
"label_definitions": {
"quality": {
"label_options": [
"good",
"noise",
"MUA",
"artifact"
],
"exclusive": "true"
},
"putative_type": {
"label_options": [
"excitatory",
"inhibitory",
"pyramidal",
"mitral"
],
"exclusive": "false"
}
},
"manual_labels": [
{
"unit_id": "u1",
"quality": [
"good"
]
},
{
"unit_id": "u2",
"quality": [
"noise"
],
"putative_type": [
"excitatory",
"pyramidal"
]
},
{
"unit_id": "u3",
"putative_type": [
"inhibitory"
]
}
],
"merge_unit_groups": [
[
"u3",
"u6"
],
[
"u10",
"u14",
"u20"
]
],
"removed_units": [
"u31",
"u42"
]
}
The curation format can be loaded into a dictionary and directly applied to
a BaseSorting or SortingAnalyzer object using the apply_curation() function.
from spikeinterface.curation import load_curation, apply_curation
# load the curation JSON file
curation_filepath = "path/to/curation.json"
curation = load_curation(curation_filepath)
# apply the curation to the sorting output
clean_sorting = apply_curation(sorting, curation_dict_or_model=curation)
# apply the curation to the sorting analyzer
clean_sorting_analyzer = apply_curation(sorting_analyzer, curation_dict_or_model=curation)
Using the SpikeInterface GUI
We support several tools to perform manual curation of spike sorting outputs.
The first one is the SpikeInterface-GUI, a QT-based GUI that allows you to visualize and curate the spike sorting output.

To launch the GUI, you can use the plot_sorting_summary() function
and select the backend='spikeinterface_gui'.
from spikeinterface import create_sorting_analyzer
from spikeinterface.curation import apply_sortingview_curation
from spikeinterface.widgets import plot_sorting_summary
sorting_analyzer = create_sorting_analyzer(sorting=sorting, recording=recording)
# some extensions are required
sorting_analyzer.compute([
"random_spikes",
"noise_levels",
"templates",
"template_similarity",
"unit_locations",
"spike_amplitudes",
"principal_components",
"correlograms"
]
)
sorting_analyzer.compute("quality_metrics", metric_names=["snr"])
# this will open the GUI in a different window
plot_sorting_summary(sorting_analyzer=sorting_analyzer, curation=True, backend='spikeinterface_gui')
Using the sortingview web-app
Within the sortingview widgets backend (see Install sortingview), the
plot_sorting_summary() produces a powerful web-based GUI that enables manual curation
of the spike sorting output.
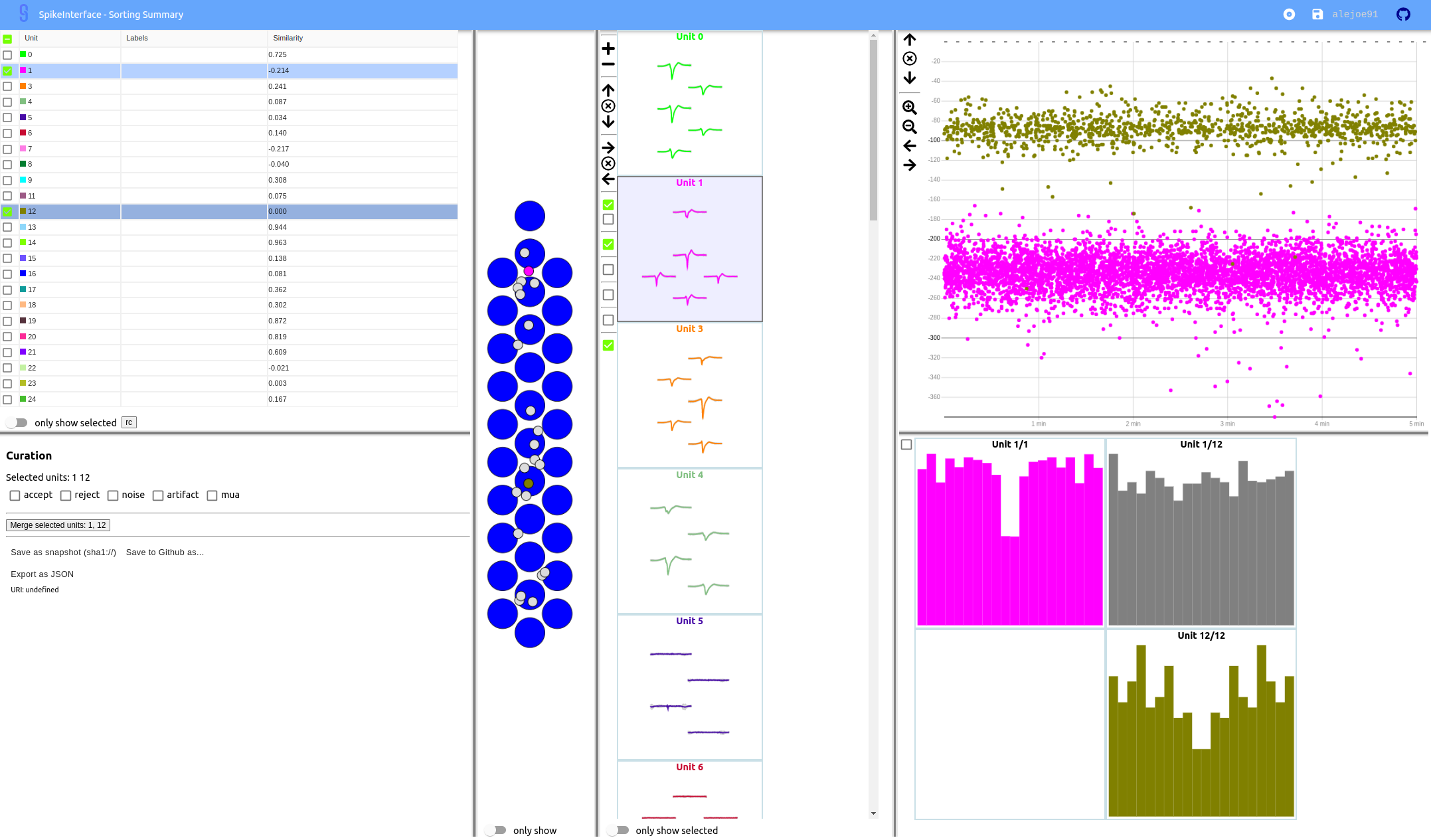
The manual curation (including merges and labels) can be applied to a SpikeInterface
BaseSorting object:
from spikeinterface import create_sorting_analyzer
from spikeinterface.curation import apply_sortingview_curation
from spikeinterface.widgets import plot_sorting_summary
sorting_analyzer = create_sorting_analyzer(sorting=sorting, recording=recording)
# some extensions are required
sorting_analyzer.compute([
"random_spikes",
"templates",
"template_similarity",
"unit_locations",
"spike_amplitudes",
"correlograms"]
)
# This loads the data to the cloud for web-based plotting and sharing
# curation=True required for allowing curation in the sortingview gui
plot_sorting_summary(sorting_analyzer=sorting_analyzer, curation=True, backend='sortingview')
# we open the printed link URL in a browser
# - make manual merges and labeling
# - from the curation box, click on "Save as snapshot (sha1://)"
# copy the uri
sha_uri = "sha1://59feb326204cf61356f1a2eb31f04d8e0177c4f1"
clean_sorting = apply_sortingview_curation(sorting=sorting_analyzer.sorting, uri_or_json=sha_uri)
Note that you can also “Export as JSON” and pass the json file as uri_or_json parameter.
The curation JSON file can be also pushed to a user-defined GitHub repository (“Save to GitHub as…”)
Other curation tools
We have other tools for cleaning spike sorting outputs:
find_duplicated_spikes(): find duplicated spikes in the spike trainsremove_excess_spikes(): remove spikes whose times are greater than therecording’s number of samples (by segment)
The CurationSorting class (deprecated)
SpikeInterface offers machinery to manually curate a sorting output and keep track of the curation history. The curation has several “steps” that can be repeated and chained:
remove/select units
split units
merge units
This functionality is done with CurationSorting class.
Internally, this class keeps the history of curation as a graph.
The merging and splitting operations are handled by the MergeUnitsSorting and
SplitUnitSorting. These two classes can also be used independently.
from spikeinterface.curation import CurationSorting
sorting = run_sorter(sorter_name='kilosort2', recording=recording)
cs = CurationSorting(parent_sorting=sorting)
# make a first merge
cs.merge(units_to_merge=['#1', '#5', '#15'])
# make a second merge
cs.merge(units_to_merge=['#11', '#21'])
# make a split
split_index = ... # some criteria on spikes
cs.split(split_unit_id='#20', indices_list=split_index)
# here is the final clean sorting
clean_sorting = cs.sorting