Note
Click here to download the full example code
Compare spike sorting output with ground-truth recordings¶
Simulated recordings or paired pipette and extracellular recordings can be used to validate spike sorting algorithms.
For comparing to ground-truth data, the
compare_sorter_to_ground_truth() function
can be used. In this recording, we have ground-truth information for all
units, so we can set exhaustive_gt to True.
Import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import spikeinterface as si
import spikeinterface.extractors as se
import spikeinterface.sorters as ss
import spikeinterface.comparison as sc
import spikeinterface.widgets as sw
- First, let’s download a simulated dataset
from the repo ‘https://gin.g-node.org/NeuralEnsemble/ephy_testing_data’
local_path = si.download_dataset(remote_path='mearec/mearec_test_10s.h5')
recording, sorting_true = se.read_mearec(local_path)
print(recording)
print(sorting_true)
MEArecRecordingExtractor: 32 channels - 1 segments - 32.0kHz - 10.000s
file_path: /home/docs/spikeinterface_datasets/ephy_testing_data/mearec/mearec_test_10s.h5
MEArecSortingExtractor: 10 units - 1 segments - 32.0kHz
file_path: /home/docs/spikeinterface_datasets/ephy_testing_data/mearec/mearec_test_10s.h5
run herdingspikes on it
sorting_HS = ss.run_herdingspikes(recording)
# Generating new position and neighbor files from data file
# Not Masking any Channels
# Sampling rate: 32000
# Localization On
# Number of recorded channels: 32
# Analysing frames: 320000; Seconds: 10.0
# Frames before spike in cutout: 10
# Frames after spike in cutout: 58
# tcuts: 42 90
# tInc: 100000
# Detection completed, time taken: 0:00:00.611362
# Time per frame: 0:00:00.001911
# Time per sample: 0:00:00.000060
Loaded 713 spikes.
Fitting dimensionality reduction using all spikes...
...projecting...
...done
Clustering...
Clustering 713 spikes...
number of seeds: 10
seeds/job: 6
using 2 cpus
[Parallel(n_jobs=2)]: Using backend LokyBackend with 2 concurrent workers.
[Parallel(n_jobs=2)]: Done 2 out of 2 | elapsed: 2.2s finished
/home/docs/checkouts/readthedocs.org/user_builds/spikeinterface/conda/0.95.0/lib/python3.8/site-packages/herdingspikes/clustering/mean_shift_.py:242: DeprecationWarning: `np.bool` is a deprecated alias for the builtin `bool`. To silence this warning, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
unique = np.ones(len(sorted_centers), dtype=np.bool)
/home/docs/checkouts/readthedocs.org/user_builds/spikeinterface/conda/0.95.0/lib/python3.8/site-packages/herdingspikes/clustering/mean_shift_.py:255: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
labels = np.zeros(n_samples, dtype=np.int)
Number of estimated units: 7
cmp_gt_HS = sc.compare_sorter_to_ground_truth(sorting_true, sorting_HS, exhaustive_gt=True)
To have an overview of the match we can use the unordered agreement matrix
sw.plot_agreement_matrix(cmp_gt_HS, ordered=False)
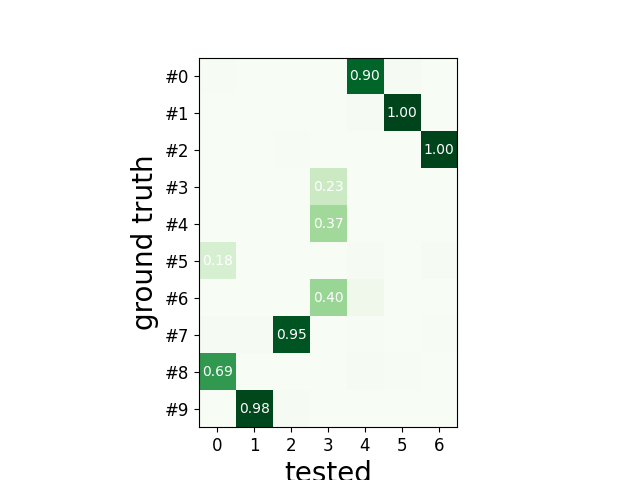
<spikeinterface.widgets._legacy_mpl_widgets.agreementmatrix.AgreementMatrixWidget object at 0x7f29756561f0>
or ordered
sw.plot_agreement_matrix(cmp_gt_HS, ordered=True)
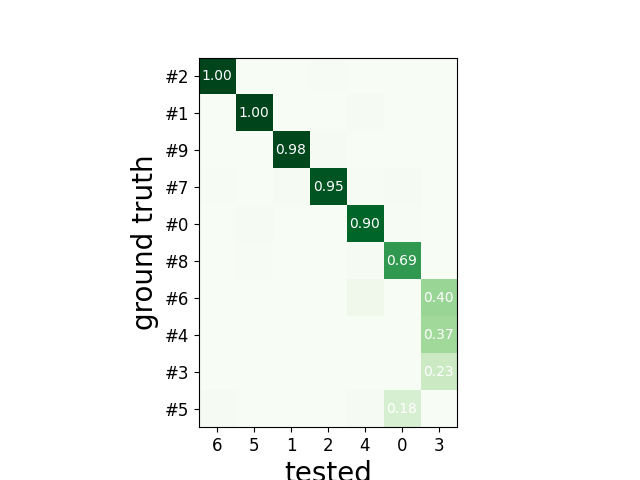
<spikeinterface.widgets._legacy_mpl_widgets.agreementmatrix.AgreementMatrixWidget object at 0x7f298c0bb2b0>
This function first matches the ground-truth and spike sorted units, and then it computes several performance metrics.
Once the spike trains are matched, each spike is labeled as:
true positive (tp): spike found both in
gt_sortingandtested_sortingfalse negative (fn): spike found in
gt_sorting, but not intested_sortingfalse positive (fp): spike found in
tested_sorting, but not ingt_sorting
From the counts of these labels the following performance measures are computed:
accuracy: #tp / (#tp+ #fn + #fp)
recall: #tp / (#tp + #fn)
precision: #tp / (#tp + #fn)
miss rate: #fn / (#tp + #fn1)
false discovery rate: #fp / (#tp + #fp)
The get_performance method a pandas dataframe (or a dictionary if
output='dict') with the comparison metrics. By default, these are
calculated for each spike train of sorting1:code:, the results can be
pooled by average (average of the metrics) and by sum (all counts are
summed and the metrics are computed then).
perf = cmp_gt_HS.get_performance()
Lets use seaborn swarm plot
fig1, ax1 = plt.subplots()
perf2 = pd.melt(perf, var_name='measurement')
ax1 = sns.swarmplot(data=perf2, x='measurement', y='value', ax=ax1)
ax1.set_xticklabels(labels=ax1.get_xticklabels(), rotation=45)
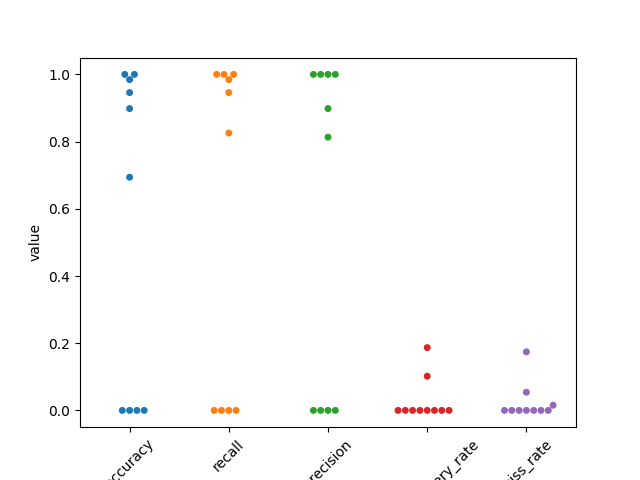
[Text(0, 0, 'accuracy'), Text(1, 0, 'recall'), Text(2, 0, 'precision'), Text(3, 0, 'false_discovery_rate'), Text(4, 0, 'miss_rate')]
The confusion matrix is also a good summary of the score as it has the same shape as agreement matrix, but it contains an extra column for FN
and an extra row for FP
sw.plot_confusion_matrix(cmp_gt_HS)
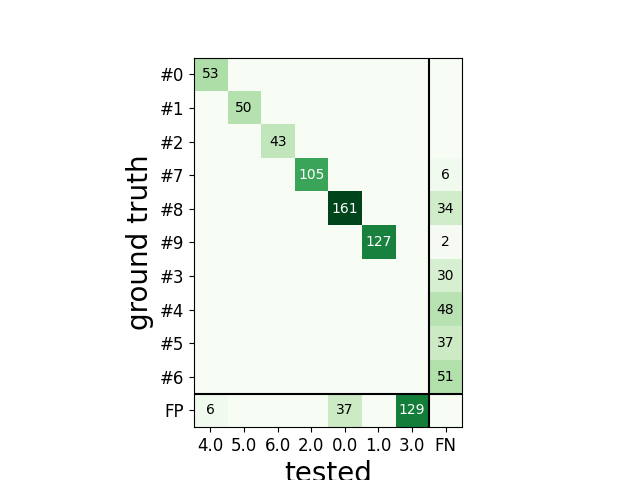
<spikeinterface.widgets._legacy_mpl_widgets.confusionmatrix.ConfusionMatrixWidget object at 0x7f29782df940>
We can query the well and bad detected units. By default, the threshold on accuracy is 0.95.
cmp_gt_HS.get_well_detected_units()
[1, 2, 4, 5, 6]
cmp_gt_HS.get_false_positive_units()
[]
cmp_gt_HS.get_redundant_units()
[]
Lets do the same for tridesclous
sorting_TDC = ss.run_tridesclous(recording)
cmp_gt_TDC = sc.compare_sorter_to_ground_truth(sorting_true, sorting_TDC, exhaustive_gt=True)
/home/docs/checkouts/readthedocs.org/user_builds/spikeinterface/conda/0.95.0/lib/python3.8/site-packages/tridesclous/dataio.py:175: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.
v1 = distutils.version.LooseVersion(tridesclous_version).version
/home/docs/checkouts/readthedocs.org/user_builds/spikeinterface/conda/0.95.0/lib/python3.8/site-packages/tridesclous/dataio.py:176: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.
v2 = distutils.version.LooseVersion(self.info['tridesclous_version']).version
/home/docs/checkouts/readthedocs.org/user_builds/spikeinterface/conda/0.95.0/lib/python3.8/site-packages/tridesclous/dataio.py:175: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.
v1 = distutils.version.LooseVersion(tridesclous_version).version
/home/docs/checkouts/readthedocs.org/user_builds/spikeinterface/conda/0.95.0/lib/python3.8/site-packages/tridesclous/dataio.py:176: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.
v2 = distutils.version.LooseVersion(self.info['tridesclous_version']).version
perf = cmp_gt_TDC.get_performance()
print(perf)
accuracy recall precision false_discovery_rate miss_rate
gt_unit_id
#0 1.0 1.0 1.0 0.0 0.0
#1 1.0 1.0 1.0 0.0 0.0
#2 0.976744 0.976744 1.0 0.0 0.023256
#3 1.0 1.0 1.0 0.0 0.0
#4 1.0 1.0 1.0 0.0 0.0
#5 0 0 0 0 0
#6 1.0 1.0 1.0 0.0 0.0
#7 0.990991 0.990991 1.0 0.0 0.009009
#8 0.974619 0.984615 0.989691 0.010309 0.015385
#9 1.0 1.0 1.0 0.0 0.0
sw.plot_agreement_matrix(cmp_gt_TDC, ordered=True)
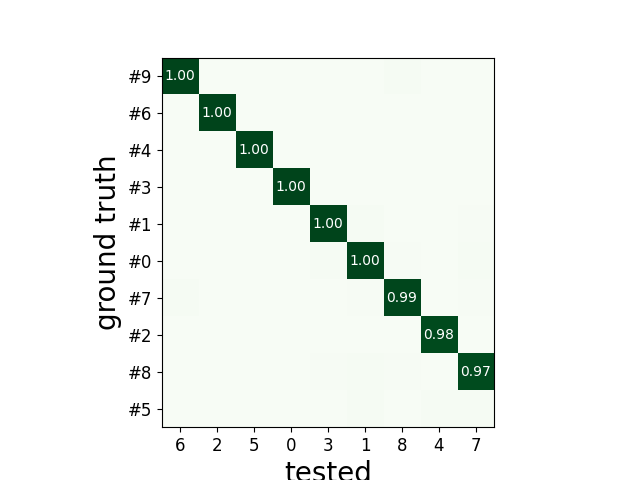
<spikeinterface.widgets._legacy_mpl_widgets.agreementmatrix.AgreementMatrixWidget object at 0x7f297563fa00>
Lets use seaborn swarm plot
fig2, ax2 = plt.subplots()
perf2 = pd.melt(perf, var_name='measurement')
ax2 = sns.swarmplot(data=perf2, x='measurement', y='value', ax=ax2)
ax2.set_xticklabels(labels=ax2.get_xticklabels(), rotation=45)
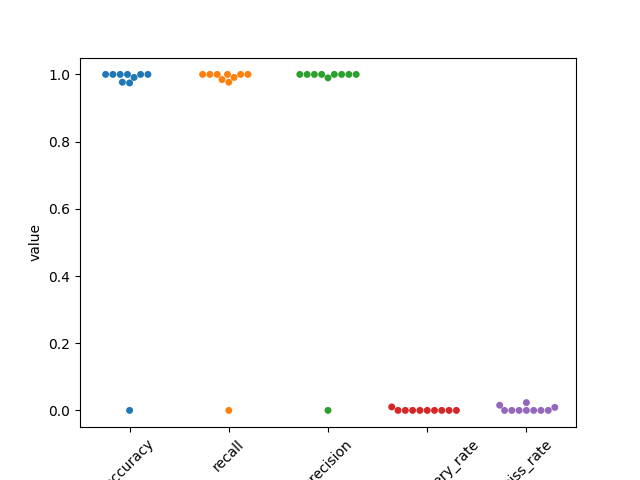
[Text(0, 0, 'accuracy'), Text(1, 0, 'recall'), Text(2, 0, 'precision'), Text(3, 0, 'false_discovery_rate'), Text(4, 0, 'miss_rate')]
print(cmp_gt_TDC.get_well_detected_units)
<bound method GroundTruthComparison.get_well_detected_units of <spikeinterface.comparison.paircomparisons.GroundTruthComparison object at 0x7f297563fd30>>
print(cmp_gt_TDC.get_false_positive_units())
[]
print(cmp_gt_TDC.get_redundant_units())
plt.show()
[]
Total running time of the script: ( 0 minutes 15.267 seconds)