Note
Click here to download the full example code
Compare two sorters¶
This example show how to compare the result of two sorters.
Import
import numpy as np
import matplotlib.pyplot as plt
import spikeinterface.extractors as se
import spikeinterface.sorters as ss
import spikeinterface.comparison as sc
import spikeinterface.widgets as sw
First, let’s create a toy example:
recording, sorting = se.example_datasets.toy_example(num_channels=4, duration=10, seed=0)
Then run two spike sorters and compare their ouput.
sorting_KL = ss.run_klusta(recording)
sorting_MS4 = ss.run_mountainsort4(recording)
Out:
RUNNING SHELL SCRIPT: /home/docs/checkouts/readthedocs.org/user_builds/spikeinterface/checkouts/0.13.0/examples/modules/comparison/klusta_output/run_klusta.sh
/home/docs/checkouts/readthedocs.org/user_builds/spikeinterface/checkouts/0.13.0/doc/sources/spikesorters/spikesorters/basesorter.py:158: ResourceWarning: unclosed file <_io.TextIOWrapper name=63 encoding='UTF-8'>
self._run(recording, self.output_folders[i])
Warning! The recording is already filtered, but Mountainsort4 filter is enabled. You can disable filters by setting 'filter' parameter to False
The compare_two_sorters function allows us to compare the spike
sorting output. It returns a SortingComparison object, with methods
to inspect the comparison output easily. The comparison matches the
units by comparing the agreement between unit spike trains.
Let’s see how to inspect and access this matching.
cmp_KL_MS4 = sc.compare_two_sorters(sorting1=sorting_KL, sorting2=sorting_MS4,
sorting1_name='klusta', sorting2_name='ms4')
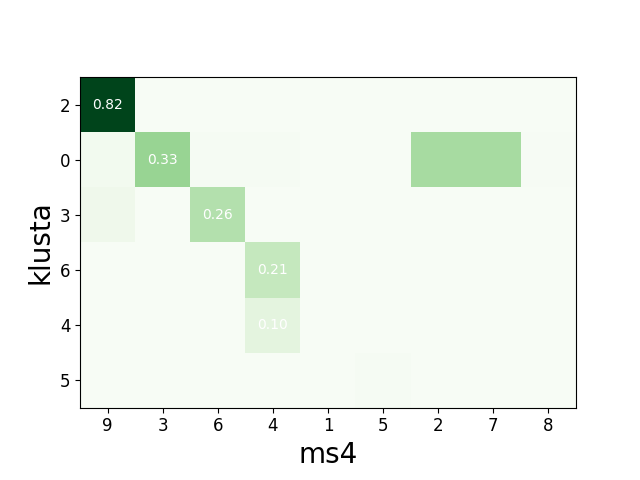
We can check the agreement matrix to inspect the matching.
sw.plot_agreement_matrix(cmp_KL_MS4)
Out:
<spikewidgets.widgets.agreementmatrixwidget.agreementmatrixwidget.AgreementMatrixWidget object at 0x7f3dfc30a160>
Some useful internal dataframes help to check the match and count like match_event_count or agreement_scores
print(cmp_KL_MS4.match_event_count)
print(cmp_KL_MS4.agreement_scores)
Out:
1 2 3 4 5 6 7 8 9
0 0 22 25 1 0 1 22 2 3
2 0 0 0 0 0 0 0 0 27
3 0 0 0 0 0 11 0 0 2
4 0 0 0 8 0 0 0 0 0
5 0 0 0 0 1 0 0 0 0
6 0 0 0 16 0 0 0 0 0
1 2 3 4 ... 6 7 8 9
0 0.0 0.289474 0.328947 0.006579 ... 0.008621 0.289474 0.005865 0.028302
2 0.0 0.000000 0.000000 0.000000 ... 0.000000 0.000000 0.000000 0.818182
3 0.0 0.000000 0.000000 0.000000 ... 0.255814 0.000000 0.000000 0.045455
4 0.0 0.000000 0.000000 0.103896 ... 0.000000 0.000000 0.000000 0.000000
5 0.0 0.000000 0.000000 0.000000 ... 0.000000 0.000000 0.000000 0.000000
6 0.0 0.000000 0.000000 0.207792 ... 0.000000 0.000000 0.000000 0.000000
[6 rows x 9 columns]
In order to check which units were matched, the get_mapped_sorting
methods can be used. If units are not matched they are listed as -1.
# units matched to klusta units
mapped_sorting_klusta = cmp_KL_MS4.get_mapped_sorting1()
print('Klusta units:', sorting_KL.get_unit_ids())
print('Klusta mapped units:', mapped_sorting_klusta.get_mapped_unit_ids())
# units matched to ms4 units
mapped_sorting_ms4 = cmp_KL_MS4.get_mapped_sorting2()
print('Mountainsort units:',sorting_MS4.get_unit_ids())
print('Mountainsort mapped units:',mapped_sorting_ms4.get_mapped_unit_ids())
Out:
Klusta units: [0, 2, 3, 4, 5, 6]
Klusta mapped units: [-1, 9, -1, -1, -1, -1]
Mountainsort units: [1, 2, 3, 4, 5, 6, 7, 8, 9]
Mountainsort mapped units: [-1, -1, -1, -1, -1, -1, -1, -1, 2]
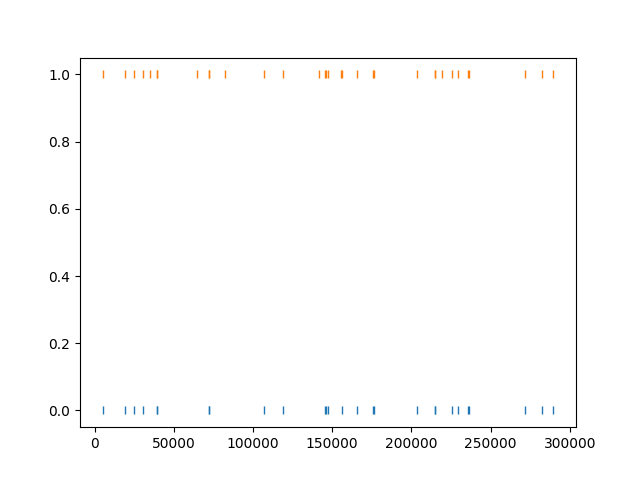
The :code:get_unit_spike_train` returns the mapped spike train. We can use it to check the spike times.
# find a unit from KL that have a match
ind = np.where(np.array(mapped_sorting_klusta.get_mapped_unit_ids())!=-1)[0][0]
u1 = sorting_KL.get_unit_ids()[ind]
print(ind, u1)
# check that matched spike trains correspond
st1 = sorting_KL.get_unit_spike_train(u1)
st2 = mapped_sorting_klusta.get_unit_spike_train(u1)
fig, ax = plt.subplots()
ax.plot(st1, np.zeros(st1.size), '|')
ax.plot(st2, np.ones(st2.size), '|')
plt.show()
Out:
1 2
Total running time of the script: ( 0 minutes 3.869 seconds)