Note
Go to the end to download the full example code
Waveform Extractor¶
SpikeInterface provides an efficient mechanism to extract waveform snippets.
The WaveformExtractor class:
randomly samples a subset spikes with max_spikes_per_unit
extracts all waveforms snippets for each unit
saves waveforms in a local folder
can load stored waveforms
retrieves template (average or median waveform) for each unit
Here the how!
import matplotlib.pyplot as plt
from spikeinterface import download_dataset
from spikeinterface import WaveformExtractor, extract_waveforms
import spikeinterface.extractors as se
First let’s use the repo https://gin.g-node.org/NeuralEnsemble/ephy_testing_data to download a MEArec dataset. It is a simulated dataset that contains “ground truth” sorting information:
repo = 'https://gin.g-node.org/NeuralEnsemble/ephy_testing_data'
remote_path = 'mearec/mearec_test_10s.h5'
local_path = download_dataset(repo=repo, remote_path=remote_path, local_folder=None)
[INFO] Cloning dataset to Dataset(/home/docs/spikeinterface_datasets/ephy_testing_data)
[INFO] Attempting to clone from https://gin.g-node.org/NeuralEnsemble/ephy_testing_data to /home/docs/spikeinterface_datasets/ephy_testing_data
[INFO] Start enumerating objects
[INFO] Start counting objects
[INFO] Start compressing objects
[INFO] Start receiving objects
[INFO] Start resolving deltas
[INFO] Completed clone attempts for Dataset(/home/docs/spikeinterface_datasets/ephy_testing_data)
install(ok): /home/docs/spikeinterface_datasets/ephy_testing_data (dataset)
get(ok): mearec/mearec_test_10s.h5 (file) [from origin...]
Let’s now instantiate the recording and sorting objects:
recording = se.MEArecRecordingExtractor(local_path)
print(recording)
sorting = se.MEArecSortingExtractor(local_path)
print(recording)
MEArecRecordingExtractor: 32 channels - 1 segments - 32.0kHz - 10.000s
file_path: /home/docs/spikeinterface_datasets/ephy_testing_data/mearec/mearec_test_10s.h5
MEArecRecordingExtractor: 32 channels - 1 segments - 32.0kHz - 10.000s
file_path: /home/docs/spikeinterface_datasets/ephy_testing_data/mearec/mearec_test_10s.h5
The MEArec dataset already contains a probe object that you can retrieve an plot:
probe = recording.get_probe()
print(probe)
from probeinterface.plotting import plot_probe
plot_probe(probe)
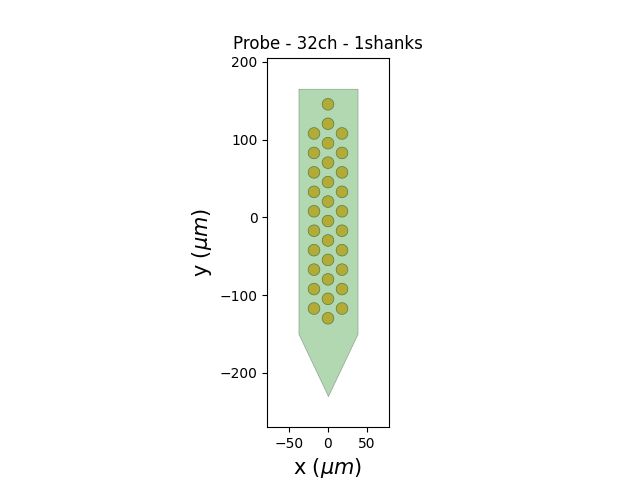
Probe - 32ch - 1shanks
(<matplotlib.collections.PolyCollection object at 0x7f6ae6a00e20>, <matplotlib.collections.PolyCollection object at 0x7f6ae69d25e0>)
A WaveformExtractor object can be created with the
extract_waveforms() function:
folder = 'waveform_folder'
we = extract_waveforms(
recording,
sorting,
folder,
ms_before=1.5,
ms_after=2.,
max_spikes_per_unit=500,
overwrite=True
)
print(we)
extract waveforms memmap: 0%| | 0/10 [00:00<?, ?it/s]
extract waveforms memmap: 90%|######### | 9/10 [00:00<00:00, 86.89it/s]
extract waveforms memmap: 100%|##########| 10/10 [00:00<00:00, 87.33it/s]
WaveformExtractor: 32 channels - 10 units - 1 segments
before:48 after:64 n_per_units:500
Alternatively, the WaveformExtractor object can be instantiated
directly. In this case, we need to set_params() to set the desired
parameters:
folder = 'waveform_folder2'
we = WaveformExtractor.create(recording, sorting, folder, remove_if_exists=True)
we.set_params(ms_before=3., ms_after=4., max_spikes_per_unit=1000)
we.run_extract_waveforms(n_jobs=1, chunk_size=30000, progress_bar=True)
print(we)
extract waveforms memmap: 0%| | 0/11 [00:00<?, ?it/s]
extract waveforms memmap: 91%|######### | 10/11 [00:00<00:00, 98.66it/s]
extract waveforms memmap: 100%|##########| 11/11 [00:00<00:00, 99.83it/s]
WaveformExtractor: 32 channels - 10 units - 1 segments
before:96 after:128 n_per_units:1000
To speed up computation, waveforms can also be extracted using parallel
processing (recommended!). We can define some 'job_kwargs' to pass
to the function as extra arguments:
job_kwargs = dict(n_jobs=2, chunk_duration="1s", progress_bar=True)
folder = 'waveform_folder_parallel'
we = extract_waveforms(
recording,
sorting,
folder,
ms_before=3.,
ms_after=4.,
max_spikes_per_unit=500,
overwrite=True,
**job_kwargs
)
print(we)
extract waveforms memmap: 0%| | 0/10 [00:00<?, ?it/s]
extract waveforms memmap: 10%|# | 1/10 [00:00<00:03, 2.40it/s]
extract waveforms memmap: 50%|##### | 5/10 [00:00<00:00, 11.93it/s]
extract waveforms memmap: 100%|##########| 10/10 [00:00<00:00, 16.87it/s]
WaveformExtractor: 32 channels - 10 units - 1 segments
before:96 after:128 n_per_units:500
- The
'waveform_folder'folder contains: the dumped recording (json)
the dumped sorting (json)
the parameters (json)
a subfolder with “waveforms_XXX.npy” and “sampled_index_XXX.npy”
import os
print(os.listdir(folder))
print(os.listdir(folder + '/waveforms'))
['waveforms', 'recording.json', 'sorting.json', 'templates_average.npy', 'params.json', 'recording_info']
['sampled_index_#7.npy', 'waveforms_#0.npy', 'waveforms_#3.npy', 'waveforms_#9.npy', 'sampled_index_#2.npy', 'waveforms_#8.npy', 'sampled_index_#5.npy', 'sampled_index_#1.npy', 'waveforms_#7.npy', 'sampled_index_#9.npy', 'sampled_index_#4.npy', 'waveforms_#4.npy', 'waveforms_#1.npy', 'sampled_index_#0.npy', 'sampled_index_#8.npy', 'sampled_index_#3.npy', 'sampled_index_#6.npy', 'waveforms_#5.npy', 'waveforms_#6.npy', 'waveforms_#2.npy']
Now we can retrieve waveforms per unit on-the-fly. The waveforms shape is (num_spikes, num_sample, num_channel):
unit_ids = sorting.unit_ids
for unit_id in unit_ids:
wfs = we.get_waveforms(unit_id)
print(unit_id, ':', wfs.shape)
#0 : (53, 224, 32)
#1 : (50, 224, 32)
#2 : (43, 224, 32)
#3 : (30, 224, 32)
#4 : (48, 224, 32)
#5 : (37, 224, 32)
#6 : (51, 224, 32)
#7 : (110, 224, 32)
#8 : (194, 224, 32)
#9 : (129, 224, 32)
We can also get the template for each units either using the median or the average:
for unit_id in unit_ids[:3]:
fig, ax = plt.subplots()
template = we.get_template(unit_id=unit_id, mode='median')
print(template.shape)
ax.plot(template)
ax.set_title(f'{unit_id}')
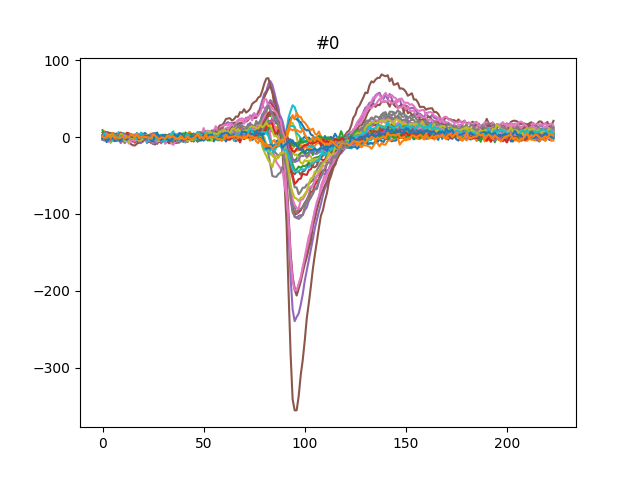
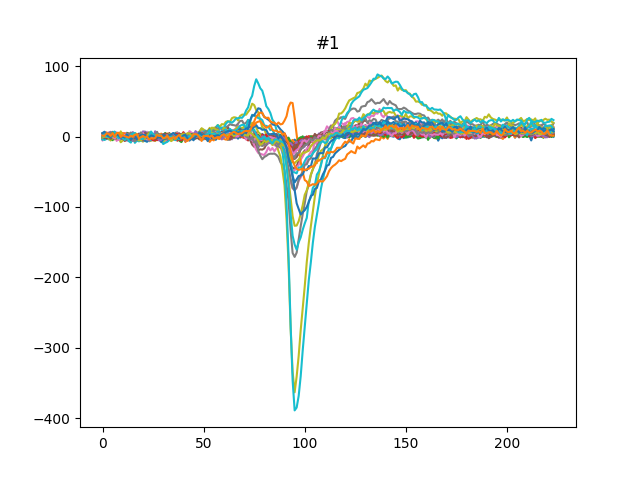
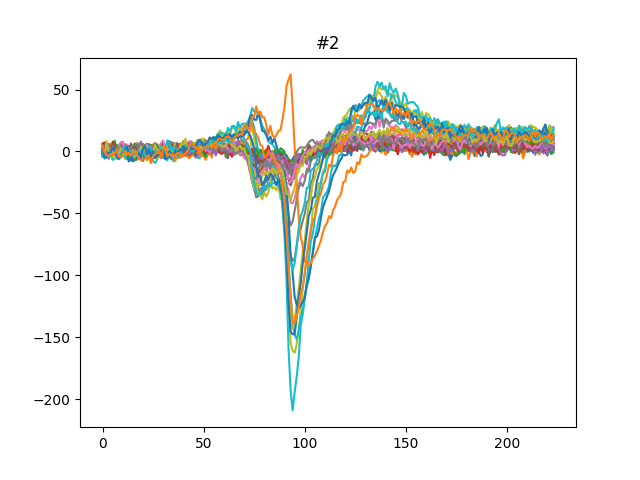
(224, 32)
(224, 32)
(224, 32)
Or retrieve templates for all units at once:
all_templates = we.get_all_templates()
print(all_templates.shape)
'''
Sparse Waveform Extractor
-------------------------
'''
(10, 224, 32)
'\nSparse Waveform Extractor\n-------------------------\n\n'
For high-density probes, such as Neuropixels, we may want to work with sparse waveforms, i.e., waveforms computed on a subset of channels. To do so, we two options.
Option 1) Save a dense waveform extractor to sparse:
In this case, from an existing waveform extractor, we can first estimate a sparsity (which channels each unit is defined on) and then save to a new folder in sparse mode:
from spikeinterface import compute_sparsity
# define sparsity within a radius of 40um
sparsity = compute_sparsity(we, method="radius", radius_um=40)
print(sparsity)
# save sparse waveforms
folder = 'waveform_folder_sparse'
we_sparse = we.save(folder=folder, sparsity=sparsity, overwrite=True)
# we_sparse is a sparse WaveformExtractor
print(we_sparse)
wf_full = we.get_waveforms(we.sorting.unit_ids[0])
print(f"Dense waveforms shape for unit {we.sorting.unit_ids[0]}: {wf_full.shape}")
wf_sparse = we_sparse.get_waveforms(we.sorting.unit_ids[0])
print(f"Sparse waveforms shape for unit {we.sorting.unit_ids[0]}: {wf_sparse.shape}")
ChannelSparsity - units: 10 - channels: 32 - ratio: 0.18
WaveformExtractor: 32 channels - 10 units - 1 segments
before:96 after:128 n_per_units:500 - sparse
Dense waveforms shape for unit #0: (53, 224, 32)
Sparse waveforms shape for unit #0: (53, 224, 6)
Option 2) Directly extract sparse waveforms:
We can also directly extract sparse waveforms. To do so, dense waveforms are
extracted first using a small number of spikes ('num_spikes_for_sparsity')
folder = 'waveform_folder_sparse_direct'
we_sparse_direct = extract_waveforms(
recording,
sorting,
folder,
ms_before=3.,
ms_after=4.,
max_spikes_per_unit=500,
overwrite=True,
sparse=True,
num_spikes_for_sparsity=100,
method="radius",
radius_um=40,
**job_kwargs
)
print(we_sparse_direct)
template_full = we.get_template(we.sorting.unit_ids[0])
print(f"Dense template shape for unit {we.sorting.unit_ids[0]}: {template_full.shape}")
template_sparse = we_sparse_direct.get_template(we.sorting.unit_ids[0])
print(f"Sparse template shape for unit {we.sorting.unit_ids[0]}: {template_sparse.shape}")
extract waveforms shared_memory: 0%| | 0/10 [00:00<?, ?it/s]
extract waveforms shared_memory: 10%|# | 1/10 [00:00<00:03, 2.52it/s]
extract waveforms shared_memory: 100%|##########| 10/10 [00:00<00:00, 20.73it/s]
extract waveforms memmap: 0%| | 0/10 [00:00<?, ?it/s]
extract waveforms memmap: 10%|# | 1/10 [00:00<00:03, 2.42it/s]
extract waveforms memmap: 70%|####### | 7/10 [00:00<00:00, 16.18it/s]
extract waveforms memmap: 100%|##########| 10/10 [00:00<00:00, 17.56it/s]
WaveformExtractor: 32 channels - 10 units - 1 segments
before:96 after:128 n_per_units:500 - sparse
Dense template shape for unit #0: (224, 32)
Sparse template shape for unit #0: (224, 6)
As shown above, when retrieving waveforms/template for a unit from a sparse
'WaveformExtractor', the waveforms are returned on a subset of channels.
To retrieve which channels each unit is associated with, we can use the sparsity
object:
# retrive channel ids for first unit:
unit_ids = we_sparse.unit_ids
channel_ids_0 = we_sparse.sparsity.unit_id_to_channel_ids[unit_ids[0]]
print(f"Channel ids associated to {unit_ids[0]}: {channel_ids_0}")
Channel ids associated to #0: ['5' '6' '7' '16' '17' '28']
However, when retrieving all templates, a dense shape is returned. This is because different channels might have a different number of sparse channels! In this case, values on channels not belonging to a unit are filled with 0s.
all_sparse_templates = we_sparse.get_all_templates()
# this is a boolean mask with sparse channels for the 1st unit
mask0 = we_sparse.sparsity.mask[0]
# Let's plot values for the first 5 samples inside and outside sparsity mask
print("Values inside sparsity:\n", all_sparse_templates[0, :5, mask0])
print("Values outside sparsity:\n", all_sparse_templates[0, :5, ~mask0])
plt.show()
Values inside sparsity:
[[ 6.7338767 3.1060634 2.8129902 1.3475728 2.3475006 ]
[ 1.953573 4.932686 4.9273763 6.148149 4.4570413 ]
[ 1.1766979 0.23954824 -0.29712072 -0.0430811 -1.0933229 ]
[ 2.9538999 3.3712146 3.991932 5.281219 2.9890084 ]
[ 1.5635666 0.10017583 0.05006344 0.44048104 2.034473 ]
[ 2.9059367 1.1767691 -0.92374414 0.08211926 0.9413183 ]]
Values outside sparsity:
[[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]]
Total running time of the script: ( 8 minutes 7.448 seconds)