Postprocessing module¶
After spike sorting, we can use the postprocessing module to further post-process
the spike sorting output. Most of the post-processing functions require a
WaveformExtractor as input.
WaveformExtractor extensions¶
There are several postprocessing tools available, and all
of them are implemented as a BaseWaveformExtractorExtension. All computations on top
of a WaveformExtractor will be saved along side the WaveformExtractor itself (sub folder, zarr path or sub dict).
This workflow is convenient to retrieve time-consuming computation (such as pca or spike amplitudes) when reloading
WaveformExtractor.
BaseWaveformExtractorExtension objects are tightly connected to the
parent WaveformExtractor object, so that operations done on the WaveformExtractor, such as saving,
loading, or selecting units, will be automatically applied to all extensions.
To check what extensions are available for a WaveformExtractor named we, you can use:
import spikeinterface as si
available_extension_names = we.get_available_extension_names()
print(available_extension_names)
["principal_components", "spike_amplitudes"]
In this case, for example, principal components and spike amplitudes have been already computed. To load the extension object you can run:
ext = we.load_extension("spike_amplitudes")
ext_data = ext.get_data()
Here ext is the extension object (in this case the SpikeAmplitudeCalculator), and ext_data will
contain the actual amplitude data. Note that different extensions might have different ways to return the extension.
You can use ext.get_data? for documentation.
We can also delete an extension:
we.delete_extension("spike_amplitudes")
Available postptocessing extensions¶
noise_levels¶
This extension computes the noise level of each channel using the median absolute deviation.
As an extension, this expects the WaveformExtractor as input and the computed values are persistent on disk.
The get_noise_levels(recording)() computes the same values, but starting from a recording
and without saving the data as an extension.
For more information, see compute_noise_levels()
principal_components¶
This extension computes the principal components of the waveforms. There are several modes available:
“by_channel_local” (default): fits one PCA model for each by_channel
“by_channel_global”: fits the same PCA model to all channels (also termed temporal PCA)
“concatenated”: contatenates all channels and fits a PCA model on the concatenated data
If the input WaveformExtractor is sparse, the sparsity is used when computing PCA.
For dense waveforms, sparsity can also be passed as an argument.
For more information, see compute_principal_components()
template_similarity¶
This extension computes the similarity of the templates to each other. This information could be used for automatic merging. Currently, the only available similarity method is the cosine similarity, which is the angle between the high-dimensional flattened template arrays. Note that cosine similarity does not take into account amplitude differences and is not well suited for high-density probes.
For more information, see compute_template_similarity()
spike_amplitudes¶
This extension computes the amplitude of each spike as the value of the traces on the extremum channel at the times of each spike.
NOTE: computing spike amplitudes is highly recommended before calculating amplitude-based quality metrics, such as Amplitude cutoff (amplitude_cutoff) and Amplitude median (amplitude_median).
For more information, see compute_spike_amplitudes()
spike_locations¶
This extension estimates the location of each spike in the sorting output. Spike location estimates can be done either
with center of mass (method="center_of_mass" - fast, but less accurate), or using a monopolar triangulation
(method="monopolar_triangulation" - slow, but more accurate).
NOTE: computing spike locations is required to compute Drift metrics (drift_ptp, drift_std, drift_mad).
For more information, see compute_spike_locations()
unit locations¶
This extension is similar to the spike_locations, but instead to estimate a location for each spike it computes
at the unit level, using the templates instead of individual waveforms. The same localization methods
(method="center_of_mass" | "monopolar_triangulation") are available.
For more information, see compute_unit_locations()
template_metrics¶
This extension computes commonly used waveform/template metrics. By default, the following metrics are computed:
“peak_to_valley”: duration between negative and positive peaks
“halfwidth”: duration in s at 50% of the amplitude
“peak_to_trough_ratio”: ratio between negative and positive peaks
“recovery_slope”: speed in V/s to recover from the negative peak to 0
“repolarization_slope”: speed in V/s to repolarize from the positive peak to 0
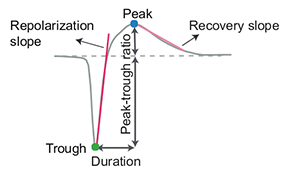
Visualization of template metrics. Image from ecephys_spike_sorting from the Allen Institute.¶
For more information, see compute_template_metrics()
correlograms¶
This extension computes correlograms (both auto- and cross-) for spike trains. The computed output is a 3d array with shape (num_units, num_units, num_bins) with all correlograms for each pair of units (diagonals are auto-correlograms).
For more information, see compute_correlograms()
isi_histograms¶
This extension computes the histograms of inter-spike-intervals. The computed output is a 2d array with shape (num_units, num_bins), with the isi histogram of each unit.
For more information, see compute_isi_histograms()
Other postprocessing tools¶
align_sorting¶
This function aligns the spike trains a BaseSorting object using pre-computed shifts of misaligned templates.
To compute shifts, one can use the get_template_extremum_channel_peak_shift() function.
For more information, see align_sorting()