Note
Go to the end to download the full example code
Explore sorters weaknesses with ground-truth comparison¶
Here a synthetic dataset will demonstrate some weaknesses.
Standard weaknesses :
not all units are detected
a unit is detected, but not all of its spikes (false negatives)
a unit is detected, but it detects too many spikes (false positives)
Other weaknesses:
detect too many units (false positive units)
detect units twice (or more) (redundant units = oversplit units)
several units are merged into one units (overmerged units)
To demonstrate this the script generate_erroneous_sorting.py generates a ground truth sorting with 10 units. We duplicate the results and modify it a bit to inject some “errors”:
unit 1 2 are perfect
unit 3 4 have medium agreement
unit 5 6 are overmerged
unit 7 is oversplit in 2 parts
unit 8 is redundant 3 times
unit 9 is missing
unit 10 has low agreement
some units in the tested data do not exist at all in GT (15, 16, 17)
Import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from spikeinterface.comparison import compare_sorter_to_ground_truth
import spikeinterface.widgets as sw
# local file
from generate_erroneous_sorting import generate_erroneous_sorting
Here is the agreement matrix
sorting_true, sorting_err = generate_erroneous_sorting()
comp = compare_sorter_to_ground_truth(sorting_true, sorting_err, exhaustive_gt=True)
sw.plot_agreement_matrix(comp, ordered=False)
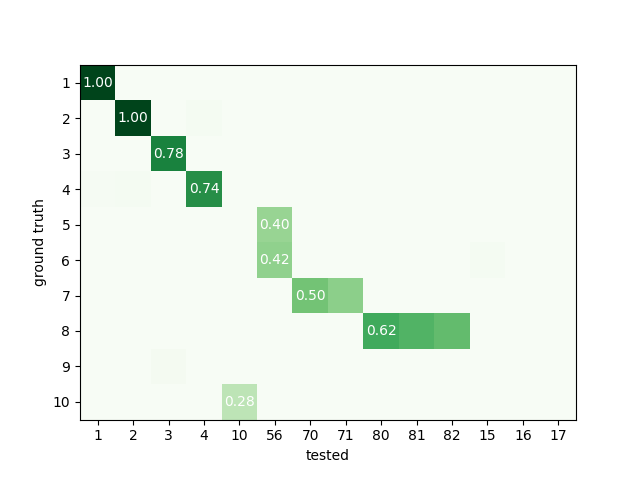
<spikeinterface.widgets.comparison.AgreementMatrixWidget object at 0x7fd5a8e42b60>
Here is the same matrix but ordered It is now quite trivial to check that fake injected errors are here.
sw.plot_agreement_matrix(comp, ordered=True)
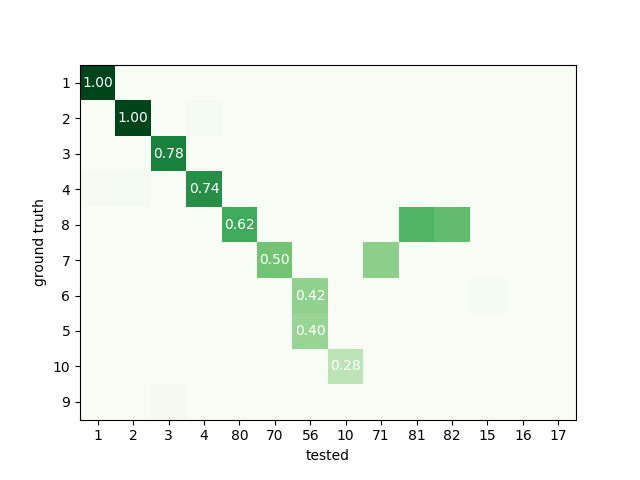
<spikeinterface.widgets.comparison.AgreementMatrixWidget object at 0x7fd5a66c9690>
Here we can see that only Units 1 2 and 3 are well detected with ‘accuracy’>0.75
print("well_detected", comp.get_well_detected_units(well_detected_score=0.75))
well_detected [1, 2, 3]
Here we can explore “false positive units” units that do not exists in ground truth
print("false_positive", comp.get_false_positive_units(redundant_score=0.2))
false_positive [15, 16, 17]
Here we can explore “redundant units” units that do not exists in ground truth
print("redundant", comp.get_redundant_units(redundant_score=0.2))
redundant [71, 81, 82]
Here we can explore “overmerged units” units that do not exists in ground truth
print("overmerged", comp.get_overmerged_units(overmerged_score=0.2))
overmerged [56]
Here we can explore “bad units” units that have a mix of several possible errors.
print("bad", comp.get_bad_units())
bad [10, 56, 71, 81, 82, 15, 16, 17]
Here is a convenient function to summarize everything.
comp.print_summary(well_detected_score=0.75, redundant_score=0.2, overmerged_score=0.2)
plt.show()
SUMMARY
-------
GT num_units: 10
TESTED num_units: 14
num_well_detected: 3
num_redundant: 3
num_overmerged: 1
num_false_positive_units 3
num_bad: 8
Total running time of the script: (0 minutes 0.885 seconds)